Convolutional Neural Network : The only introduction that you need !

With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.
If you are looking for some resource that could help you to understand the way CNN works in a simple way, then let me tell you that you are at the right place, because after reading this blog post I can assure you that you will be fully equipped with the knowledge regarding CNN architecture and how it works with amazing visuals. So let’s begin without any further due
What is CNN and why we use them ?
CNN which stands for Convolutional neural network is simply a type of neural network that is specifically designed to work with image data for solving classification and regression problems .

Now before moving on to the architecture of CNN, we must be aware about why we are not using ANN at the first place and what are those reasons because of which CNN came into existence ?
So to answer this query, there are basically 2 reasons because of which using ANN for image data will not be a good choice.
High computation : To better understand this point let us assume that we have a neural network with 2 hidden layers having 128 nodes each and one ouput layer with only single neuron. Now with this architecture let’s consider that we are trying to solve classification problem in which we will feed an image of 150 * 150 pixels to our ANN . Now since we know that ANN takes the data input in 1D i.e. vector , this means that in the input we will be requiring total 150 * 150 = 22,500 neurons , so when the data from the input layer will be passed to hidden layer neuron , then it is obvious that some weights will be assigned and total number of those would be around ( 22,500 * 100 ) = 22,500,00 weights now with so many learnable parameters our ANN will take lot of time to train and also a lot of computational power will be required.
Loss of spatial information : We know that every image is just a combination of pixels and in case we are trying to solve some computer vision problem in such scenarios since ANN accepts data in 1D i.e. ( vector ) , we will first need to convert 2D image data ( Matrix ) to 1D data (vector) and after doing so when we will feed our ANN with the vector representation of the image , then the information regarding spatial distance between the pixels would be lost which could be used as an important feature to solve the problem.
How does CNN looks like ?
Moving on to the architecture of CNN, a CNN’s architecture is like an advanced version of ANN where apart from Fully connected neural network there are 2 additional layers ( Convolution and Pooling layer ) which makes it possible for the fully connected neural network present at the end to work with image data.
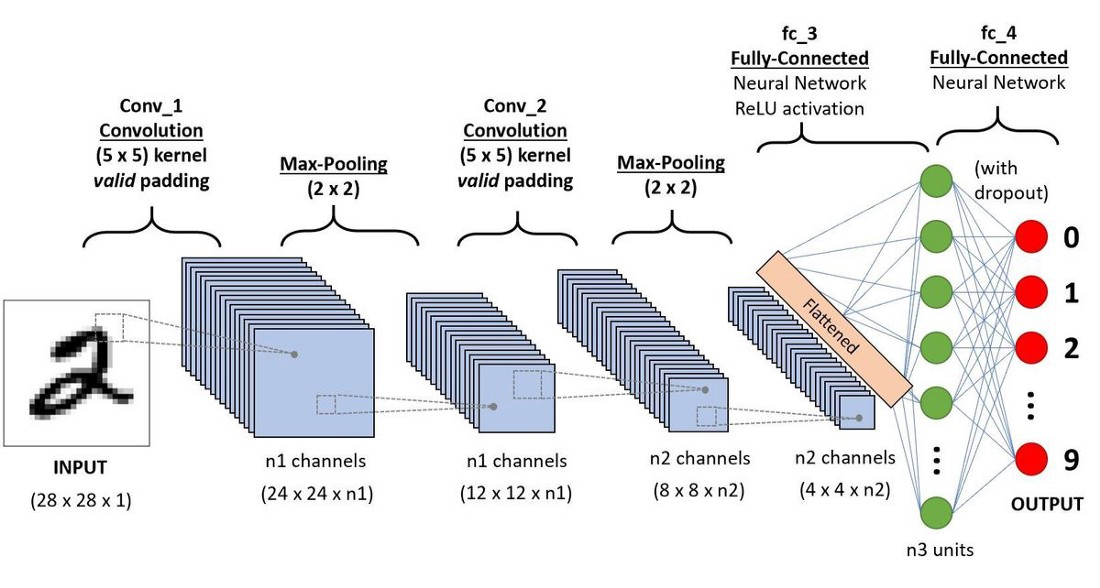
In short a CNN is composed of 3 layers : Convolutional layer , Pooling layer and fully connected neural network layer . So now let’s discuss each layer one by one .
What’s the role of the convolutional layer in CNN ?
First of all when we feed an image to CNN , then convolutional layer is the very first layer through which the image has to pass. In the convolutional layer there is a process called the covolution process which first scans the image and extract some important features from the image .
But before moving on to details of convolution process let us first understand what does a filter mean , because at the core convolution process is done by the filter itself.
Filter is simply a matrix of nn dimensions that is used to extract features from the images by convolving through nn blocks of pixels of the image.
Now moving on to how the convolution process works . Basically first of all we need to define the number of filters and the dimension of those filters which will convolve through image to extract features from the image .
After defining the filters and dimension of those filters the very first filter of nn dimension will start convolving through nn block of pixles of the image and the dot product of the 2 matrix will take place .
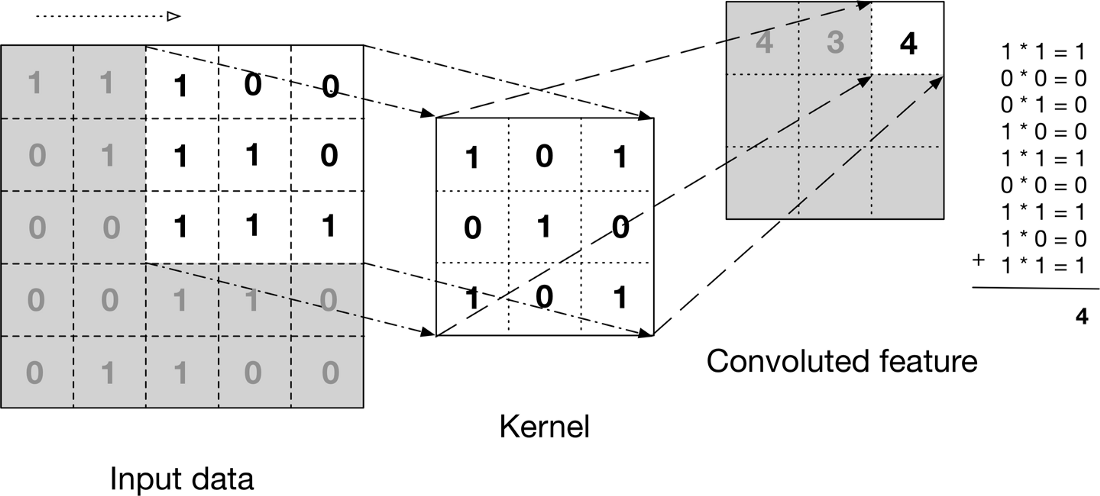
Now let us see how the convolution process will take place for the entire image of 5 * 5 pixels and filter size of 3 * 3 dimensions
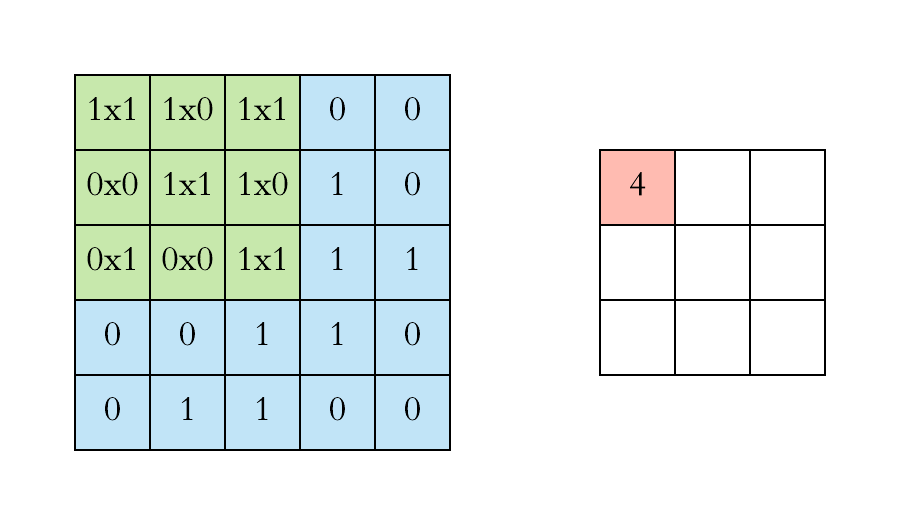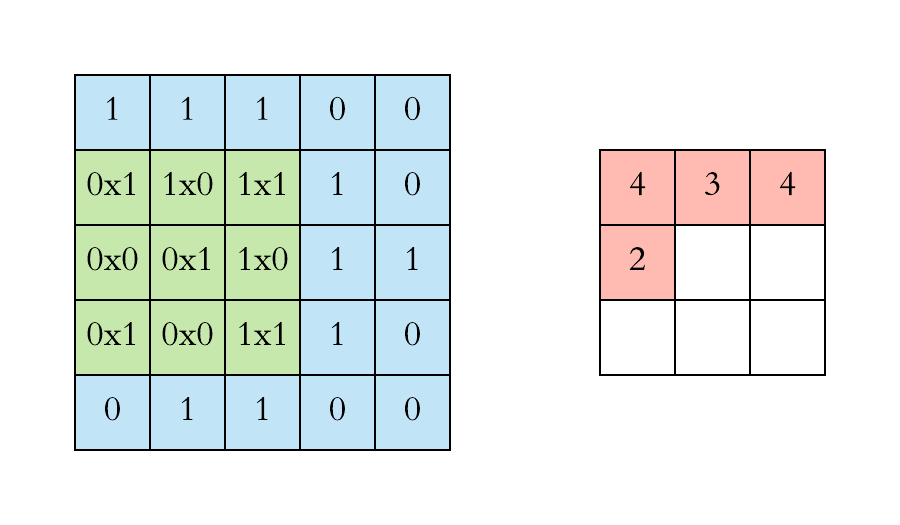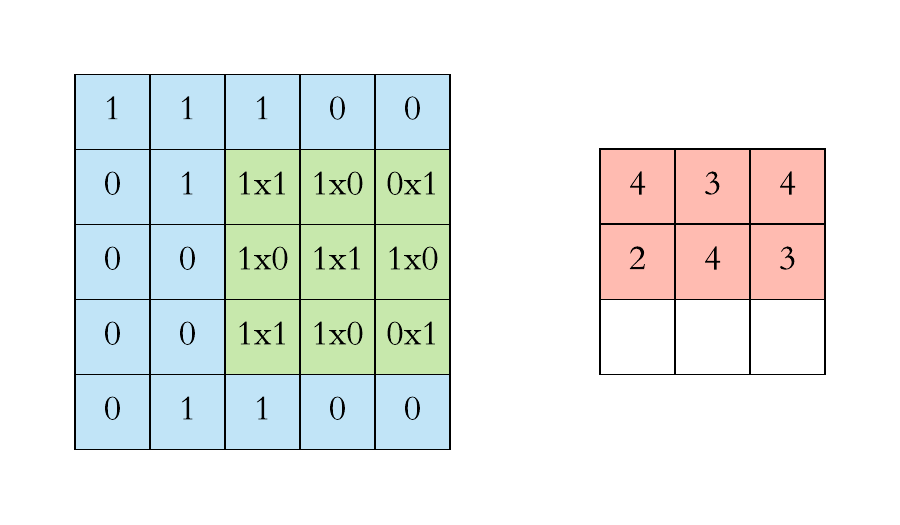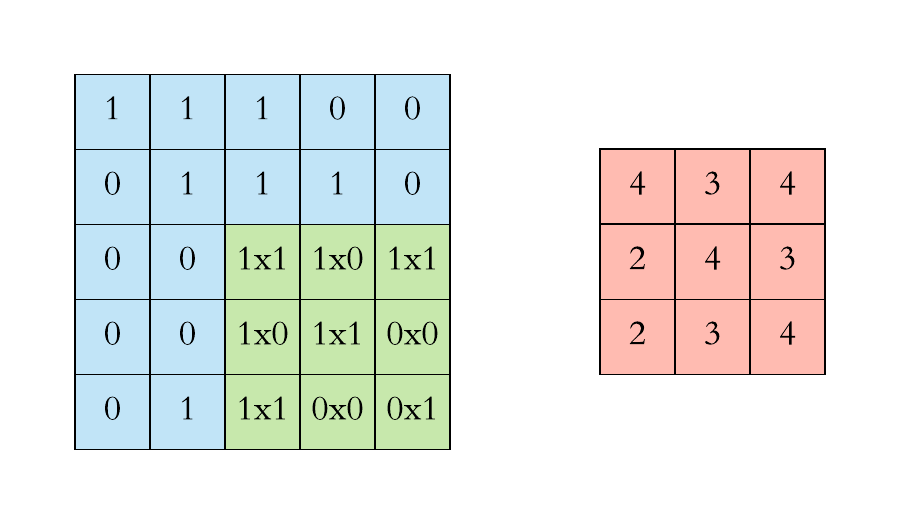
Before moving further , the thing to keep in mind is that in case of RGB image we will be having 3 seperate filter each for an individual channel ( Red, Blue , Green) and in case of RBG image convolution process will look something like ⬇️
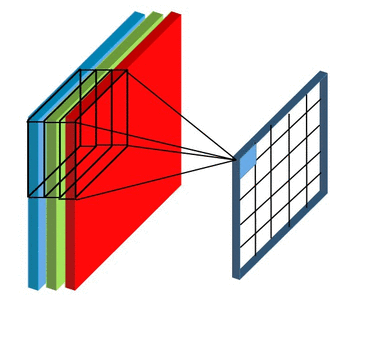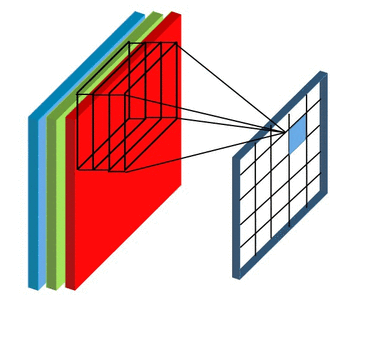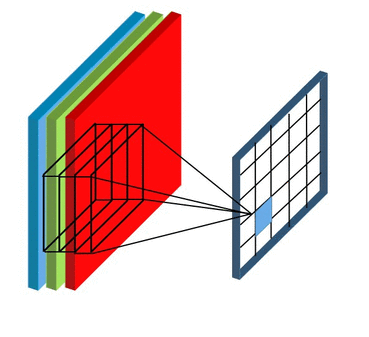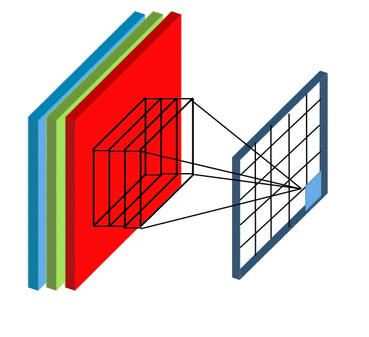
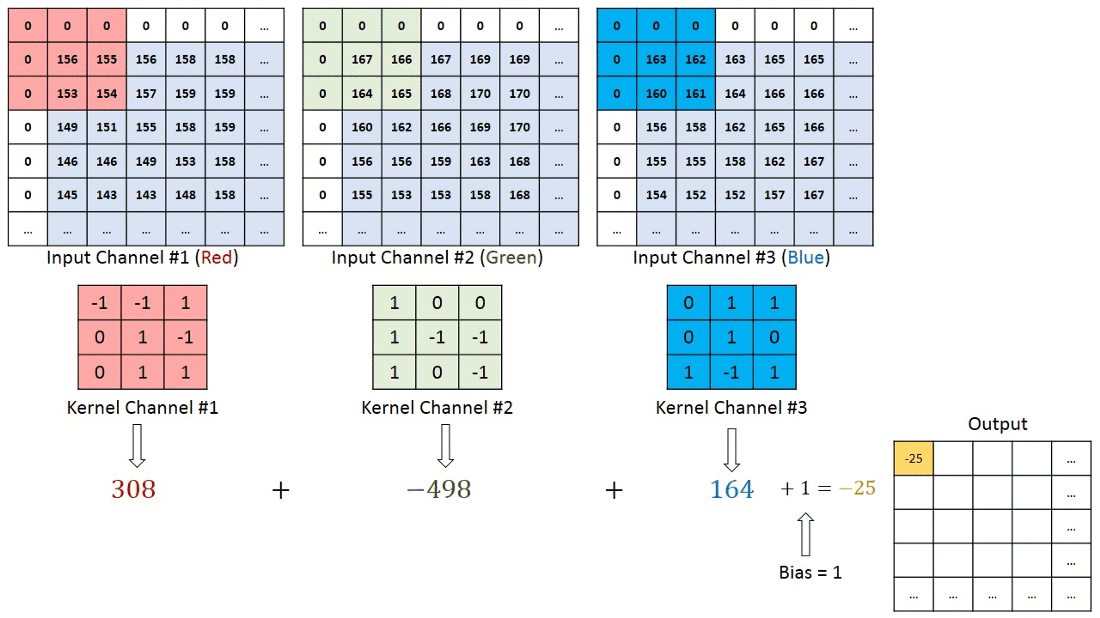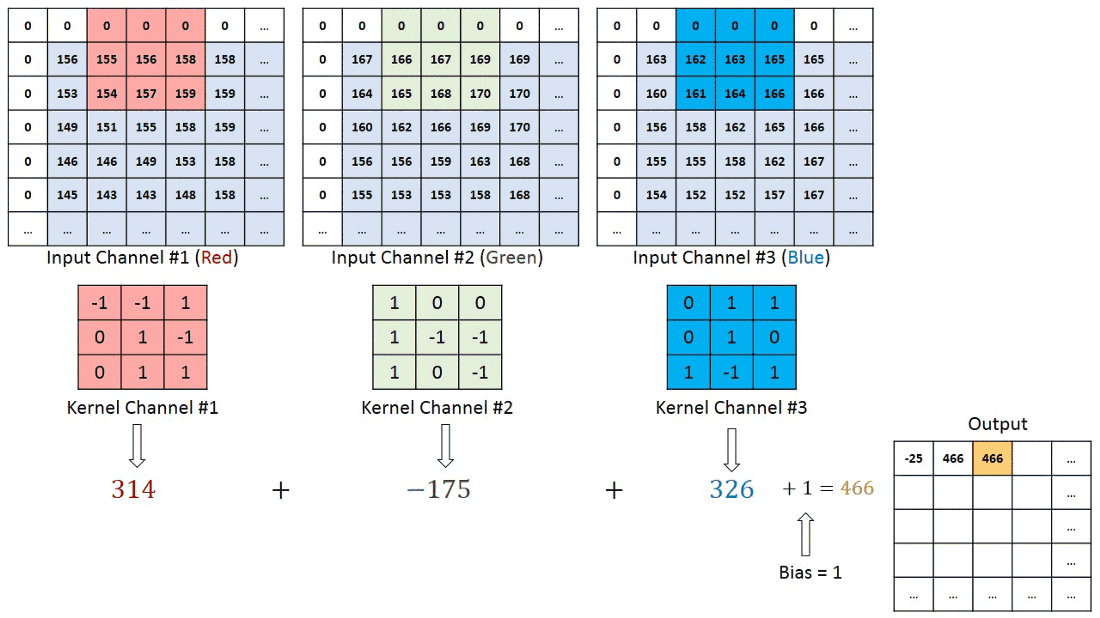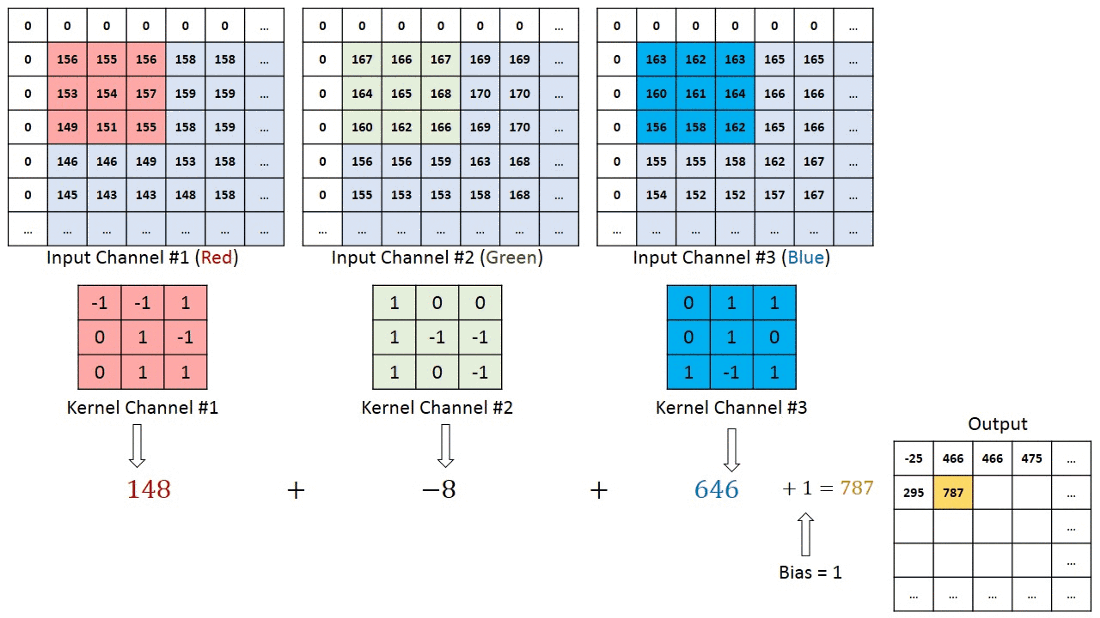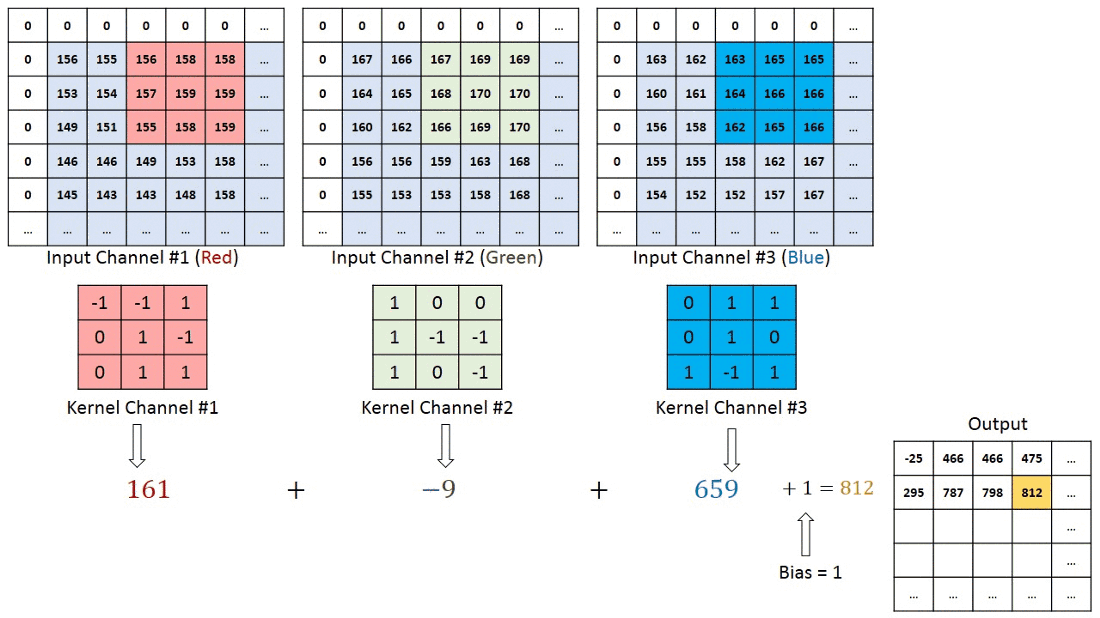
Now you might be having doubt regarding , if we are using seperate filters for individual channels in RGB image then what about the final output value which we get after every convolution process ?
In case of RBG image the final output after one convolution process will finsih will simply be the addition of output values from the individual matrix multiplication of filter with the corresponding channels
How to find the dimensions of the feature map ?
Before taking a look at the way to find the dimensions of the feature map , you must be aware about the fact that the matrix which we get after a filter convolve through the entire image is calleda feature map.
Formula to find dimensins of feature map : ( n — f + 1 ) * ( n — f + 1 ) , where n are the dimension of image and f are the dimension of filter.
What is padding and what's the need for it ?
First moving on to what is padding , let us first understand what were the problem which were facing and because of which the concept of padding came into existence .
Loss of information : Basically when we pass an image through a convolutional layer , the dimensions of the feature map gets reduced as compared to the original image which we feeded into the convolutinal layer . This reduction in the dimension means some of the informaton is getting lost , and when the same image passes through multiple conovlutional layer the overall dimensions of the feature map get highly reduced or we can say a lot of information gets lost , which could be used to make some features that could help our ML/DL model to learn and perform better.
Less contribution of corner pixels : During the convolution process , the pixels which are present at the corner of an image takes part in convolution operations for the least number of times as compared to the pixels present at the edges and in middle of the image , because of which contirbution of the corner pixels in the final feature map is minimum.
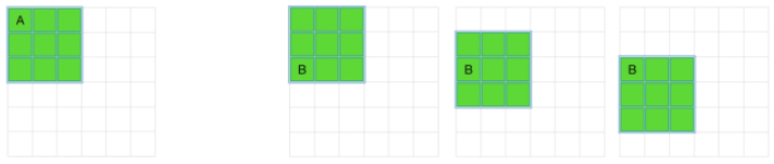
So in order to prevent the loss of information and to increase the contribution of edge pixels in the feature map , the concept of padding came into existence in which we add some cushioning to the image so that when the image passes through a convolutional layer the information is not getting lost and also the edge pixles are taking part in more number of convolution operations
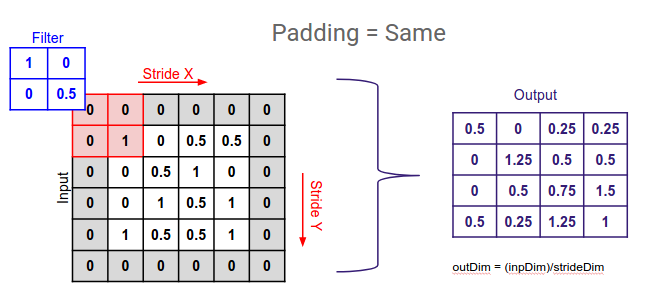
What is meant by stride ?
Stride is simply a hyperparameter of a conovlutional neural network which is used to define the amount of movement of the filter while convolving over the image.
What is pooling laer in CNN and why we need it ?
Before diving deep into what’s the use of pooling layer and how does the pooling layer work , let us first understand that why we need pooling layer at all , what were the reasons because of which we started adding pooling layer in CNN ?
Memory Issue : To better understand this point let us assume that we have an image of dimensions 228* 228 pixels and around 100 filters of dimension 3 3 each , now we know that the dimensions of the feature map which we will recieve from every filter after completing convolution operation will be 226226. So the total memory which will be needed to store the feature map of single image would be around (226*226) * (100 filters ) * (32 bit) = 19 mb . Now the thing to keep in mind is that this memory will be used for storing the feature map of only one 1 image ,and usually we feed images to feature map in Batch , thus a lot of memory will be utilized to store the feature maps.
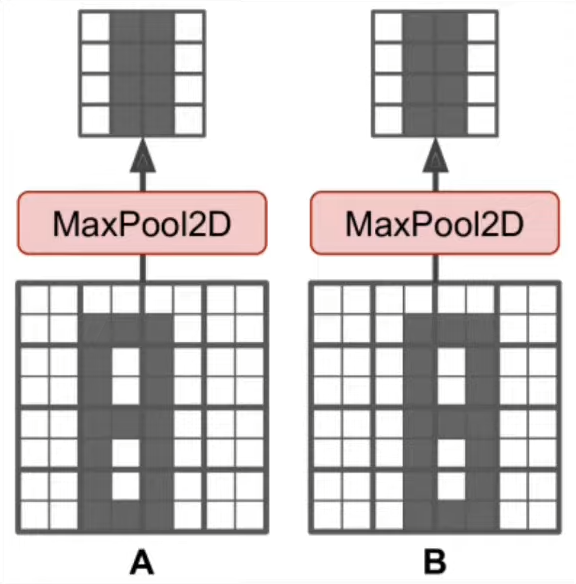
Translation Variance : Translation variance basically means that the features which will be extracted by the filters from the image will be location dependent . To better understand this point , let us assume that we have an image of some cat and we will feed the same image twice in CNN but with slight difference in the location of cat during the second time . After both the images would pass from the convolutional layer you woud observe that the features extracted will be different becaue of change in the location of cat in the image which not must be the case , because this will lead to different results for the same image !

To solve the memory issue we can increase stride lenght , but the increase in the stride lenght will not solve the problem of tranlsation variance , thus for solving both the problems we use pooling layer.
Pooling layer is basically the 2nd layer present in the CNN , which is used for reducing the dimensions of the feature map and also to make the extracted features features translational invariance i.e. independent of the location .
One important thing to keep in mind is that before the implementation of pooling operation , first relu function is used on the feature map to make it non-linear.
Now after using relu function on the feature map , for applying pooling layer on the feature map we need to specify 3 things 👇
Size of window on which pooling operation will take place
Stride
Type of pooling ( Maxpooling , Minpooling , Average pooling , L2 pooling and Global pooling )
Now in order to understand the pooling operation , let us assume that we have a feature map of dimensions 4 * 4 , and after using relu function on the feature map , we have defined that the size of window on which pooling operation will take place will be (2,2) , at the same time the stride lenght will be 1 and the type of pooling to be Maxpooling . After doing so let us take a look at the animation down below 🔽
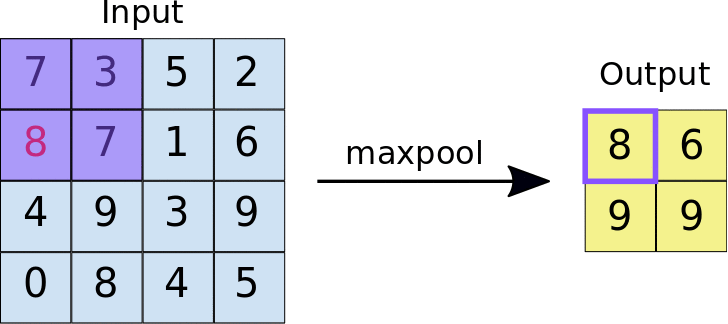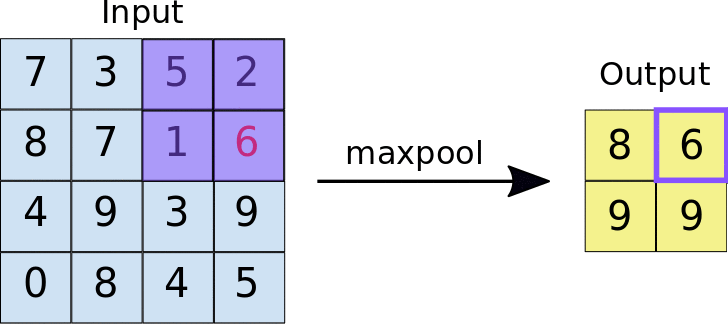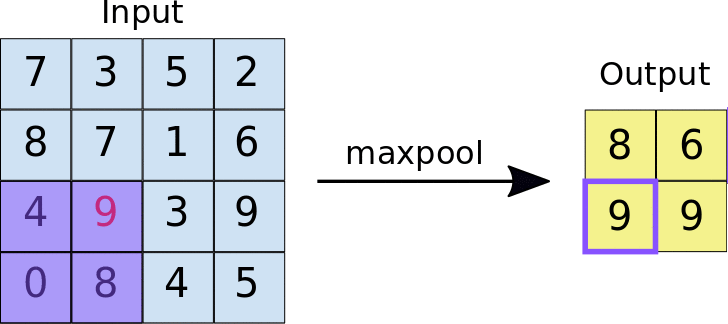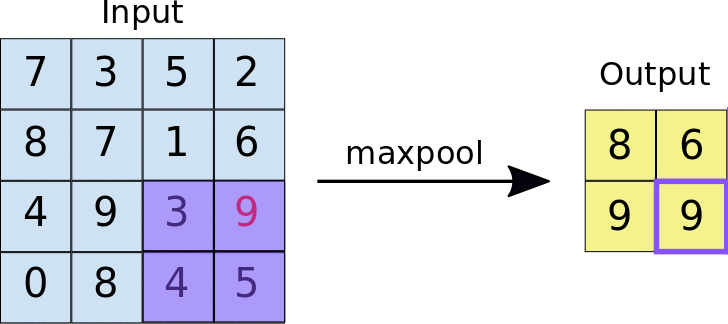
In case you are having doubt regarding how the features are becoming translation invariant after applying pooling operation , then take a look down below 👇
At the end , one thing to keep in mind is that global pooling or global average pooling can also be used as an alternative for flatten and can be used flatten the data , so that we could pass the data in the fully connected neural network .




