Cross Validation: A Powerful Tool for Machine Learning

With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.
I hope you are doing great, so today we will talk about an important and everyone's favourite Data Science interview question "Cross validation". In case you are not aware about anything related to this keyword then don't worry after reading this blog post you will be fully aware about what does this mean, why to use it and how to use it. So without any further delay let's get started.
What is cross validation ?
Cross validation is a technique in which simply divides our data into k subsets/folds and train our model on k-1 subsets and test our model performance on the remaining subsets. This overall process is repeated k times and every fold becomes test set once. Finally the average of the performance results from all k times trained model is taken into consideration.
Why do we use cross validation ?
Cross validation is used to determine generalizabilty of our model. In other we can say that it helps us to understand the overall performance of the machine learning model when trained on different training data. In case you are still not clear about why do we need cross validation then let me give you an example and by the end of this example you will get completely clear in your mind about the importance of cross validation.
Let say for training your model you have done train test split with random state=0 and after doing splitting when you trained our model you got the overall accuracy of classification model to be 96%. Now after sometime let say you again did the train test split but this time you got model accuracy to be 92%. Now this may seem to be strange at first, but if you will observe the data before and after splitting everything will get clear in your mind.
Basically with different value of random state the data points in the training and testing data changes and with this change in the training data the model performance may vary and the problem with this variability is that you can no longer be sure about the absolute performance of your model and this is not good.
So to solve this problem we divide our data into some subsets and train our model model of k-1 subsets and train our model on remaining subset, by this way we get k test scores and on the basis of those k test scores we can actually form an idea about how well our model is performing, like if the k test scores are consistent then it is good indication and it means our model is generalized but if the k test scores are varying so much then it means there is high variance.
Types of cross validation
Now we will discuss about all the different types of cross validation, along with their pros and cons, so that you would be make a fair decision about which type of cross validation technique you should use. Also I want to make this thing very much clear that may be some more different types of cross validation but for around 95% of times you will be using these types only.
Hold-out cross-validation
This is the simplest type of cross-validation. The data is split into two subsets, a training set and a test set. The model is trained on the training set and then tested on the test set. This process is repeated multiple times, with the test set being different each time.

Advantages:
Simple to implement
Requires a single data split
Disadvantages:
- Can be biased towards the training set
Leave one out Cross validation
Hold one out is a cross validation technique in which we simply divides the dataset into k subsets where k = number of data points. With this configuration the model is trained for total k times and everytime only 1 data point willl be used for testing and remaining data points for training.
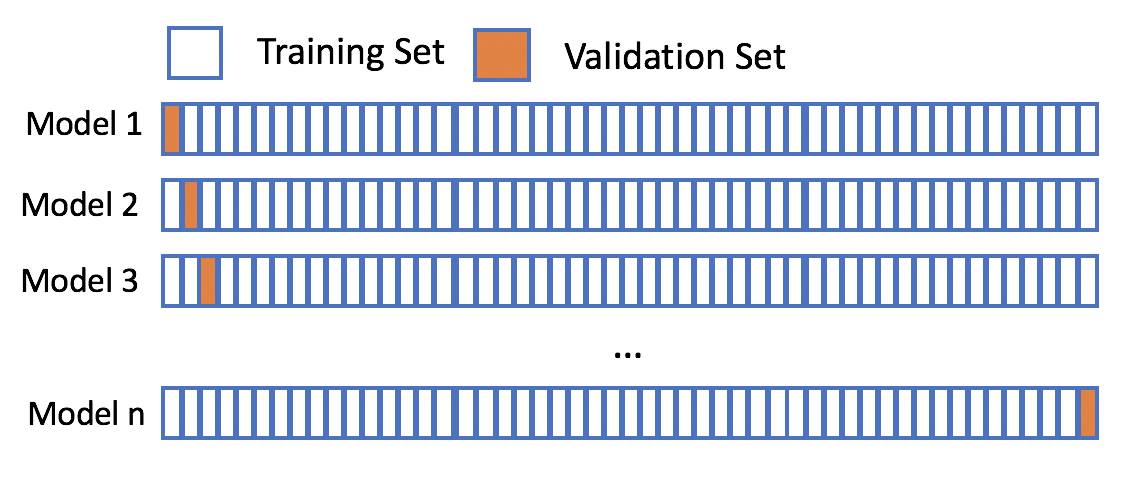
Advantages:
Simple to implement
Can be used with small datasets
Disadvantages:
Can be computationally expensive for large datasets
Sensitive to the order in which the data is split into subsets
Stratified K fold cross validation
This is a variation of k-fold cross-validation that is used when the data is stratified. This means that the data is divided into different categories, such as male and female, or high income and low income. Stratified k-fold cross-validation ensures that each fold contains a representative sample of each category.
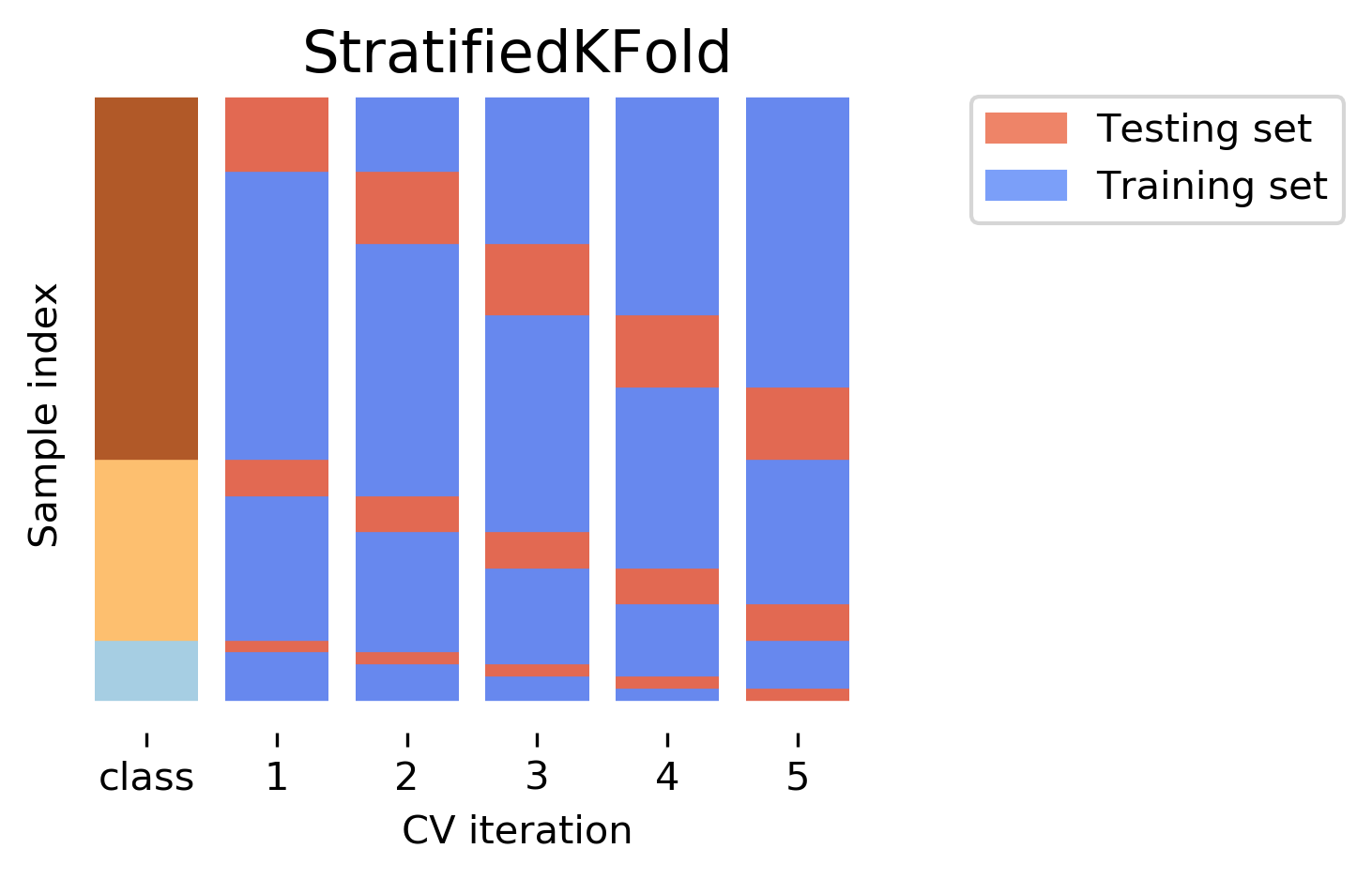
Advantages:
Reduces overfitting: Cross-validation helps to reduce overfitting by training the model on multiple subsets of the data. This means that the model is less likely to memorize the training data and more likely to generalize well to new data.
Provides a more accurate estimate of the model's performance: Cross-validation provides a more accurate estimate of the model's performance than the hold-out method because it uses multiple test sets. This means that the model's performance is less likely to be overestimated or underestimated.
Can be used to select hyperparameters: Cross-validation can be used to select hyperparameters, such as the learning rate or the regularization strength. This can help to improve the model's performance.
Disadvantages:
Can be computationally expensive: Cross-validation can be computationally expensive, especially for large datasets. This is because the model has to be trained multiple times.
Can be difficult to interpret: The results of cross-validation can be difficult to interpret, especially if the model is complex.
Leave p out ( Variant of LOO )
This is a type of cross-validation where the model is trained on all but p of the data points. The model is then tested on the p data points that were left out. This process is repeated p times, with a different set of p data points being left out each time.
Short note
I hope you good understanding of what is cross validation, why do we need it and what are the different types of cross validation. So if you liked this blog or have any suggestions kindly like this blog or leave a comment below it would mean a to me.



