Feature Scaling: A Guide for AI Developers

With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.
I hope you are doing great, so today we will discuss an important topic in machine learning called feature scaling. After going through this blog you will be completely aware about which technique to use and when to use. So without any further dealy let's get started
What is feature scaling
Feature scaling is an important part of feature engineering and in feature scaling our main aim is to simply bring all the numerical features to common scale so that no feature in our dataset overpowers other features in our dataset.
Why do we even need to do it ?
To better understand the need of need of doing feature scaling let us take an example and by the end of this example you would be completely aware about why do we even care about equalizing the scale of features.
Let say that we are solving a particular problem where based on salary and years of experience of an individual working in the company we have to predict whether a person will be promoted or not. This is is a dummy binary classification problem, so let say that we are using a simple classification algorihtms called KNN which stands for K nearest neighbor.

Now in case of KNN for the new query point we have to find the K nearest neighbor and on the basis of majority we assing a class label to the query point, so for fiding the k nearest neightbor when we will use some distance metric let say eucledian distance for simpliticity we will observe that the the salary feature will sort of overpower the impact of age of the employee. Because the salary will be mostly in terms of 1000s and age will be within the range of 20 to 60 something ( let say ) and because of this signifcant difference in the overall scale of values in both the features the final output will be having more contributions by the salary column and teh presence or absence of age feature will not making any impact.
Types of feature scaling
There are basically 3 commonly used technqiues for doing feature scaling, and these 3 techniques are standardization, normalization and robust scaling. Apart from this the mathematical transformations such as BOX COX or Yeo-Johsnon transformations are also used for scaling the values by manipulating the distribution of data to normal distribution. In this blog we will only talk about the 3 conventional feature scaling techqiues, how to implement them and when to use which technqiue.
Standardization
Standardization whci is also known as z score normalizaton is a feature scaling technique in which we use the mean and standard deviatoin of the feature to scale down the values of that feature to a common scale. Mathematicall it is defined as
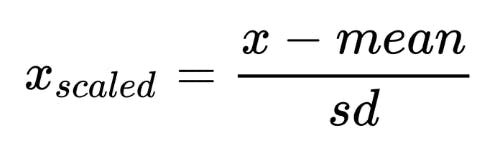
Talk about how to do it using which library and using python code.
import numpy as np
def standardize(data):
"""
Standardizes a dataset.
Args:
data: The dataset to be standardized.
Returns:
The standardized dataset.
"""
mean = np.mean(data, axis=0)
std = np.std(data, axis=0)
return (data - mean) / std
if __name__ == "__main__":
data = np.array([1, 2, 3, 4, 5])
print(standardize(data))
Normailzation
Normalization which is also known as min-max normalization is a feature scaling technique in which we transform the features values into new values which lies between the range of [0, 1]. Mathematicall it is defined as
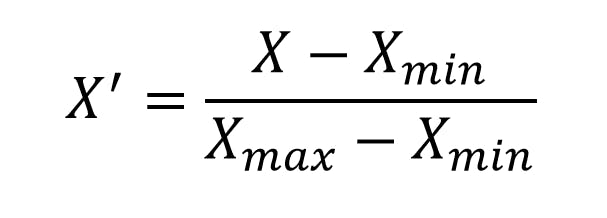
Let's now see how to do normalization of a feature using python code
import numpy as np
def min_max_normalize(data):
"""
Min-max normalizes a dataset.
Args:
data: The dataset to be normalized.
Returns:
The normalized dataset.
"""
min_val = np.min(data, axis=0)
max_val = np.max(data, axis=0)
return (data - min_val) / (max_val - min_val)
if __name__ == "__main__":
data = np.array([1, 2, 3, 4, 5])
print(min_max_normalize(data))
Short summary
Since you are now aware about what does standardization and normalization means let's now simply sum the things and compare the differences between the 2 techniques
| Standardization | Normalization |
| After applying standardization the mean of data becomes 0 and standardization becomes 1 | After doing normalization the values get transformed into new values which ranges in [0,1]. |
| new_value = (value - mean) / standard deviation | new_value = [ value - min(feature) ] / [ max(feature) - min(feature) ] |
| It is more robust to outliers | It is very much sensitive to outliers |
When to use normalization or standardization ?
For doing the feature scaling the selection of the technique is totally based on the data which we have at hand.
Incase you are not aware about the distribution of data or the algorithm which you will be using doesn't make any assumption about the distribution of data such as Tree algorithms, KNN and artificial neural networks in such scenarios it is recommended to use normalization.
The assumption behind standardization is that your data follows a Gaussian (bell curve) distribution. This isn’t required, however, it helps the approach work better if your attribute distribution is Gaussian. Also if the algorithm which you will be using makes assumption about the distribution of data then standardization would better to use.
Short Note
I hope you good understanding of what is feature scaling, how to implement the technique using python code and when to use which technique so if you liked this blog or have any suggestion kindly like this blog or leave a comment below it would mean a to me.




